How to use MongoDB Aggregation Framework: A Comprehensive Guide
Master MongoDB's powerful aggregation framework with practical examples, visualizations, and best practices for data transformation and analysis.
How to Use MongoDB Aggregation Framework: A Comprehensive Guide
Ever wondered how to transform and analyze your MongoDB data like a pro? The MongoDB Aggregation Framework is your Swiss Army knife for data processing, offering powerful tools to slice, dice, and analyze your data in ways that simple queries just can’t match. In this comprehensive guide, we’ll explore everything from basic concepts to advanced techniques, complete with practical examples and real-world applications.
Understanding MongoDB Aggregation
MongoDB’s Aggregation Framework is like a data processing pipeline where your documents flow through different transformation stages. Each stage performs a specific operation on your data, and the output from one stage becomes the input for the next. Think of it as an assembly line for your data, where each station adds value to your final result.
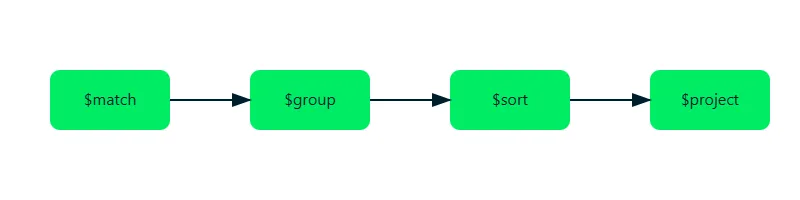
Why Use Aggregation?
Before diving into the technical details, let’s understand why you might want to use the Aggregation Framework:
- Complex Data Analysis: Perform sophisticated data analysis operations that go beyond simple CRUD operations
- Data Transformation: Transform your data into new formats or structures
- Statistical Analysis: Calculate averages, sums, and other statistical measures
- Real-time Analytics: Process and analyze data in real-time for business intelligence
- Data Mining: Discover patterns and relationships in your data
Core Concepts: The Pipeline Approach
Let’s dive into a practical example. Imagine you’re running an e-commerce platform and want to analyze your sales data.
db.sales.aggregate([
{ $match: { status: "completed" } },
{ $group: {
_id: "$product",
totalRevenue: { $sum: "$amount" },
averageOrder: { $avg: "$amount" },
count: { $sum: 1 }
}},
{ $sort: { totalRevenue: -1 }}
])
Understanding Pipeline Stages
Each stage in the pipeline serves a specific purpose:
- Initial Stage: Filters and shapes the input data
- Middle Stages: Transform and process the data
- Final Stage: Formats the output
Essential Aggregation Stages
$match Stage
The $match stage filters documents, similar to the find() method. It’s most efficient when placed early in your pipeline.
db.users.aggregate([
{ $match: {
age: { $gte: 21 },
country: "USA"
}}
])
Best Practices for $match
- Place $match as early as possible in the pipeline
- Use indexed fields in $match conditions
- Combine multiple conditions using $and when possible
$group Stage
$group is your go-to stage for summarizing data. Here’s how you might analyze user activity:
db.activities.aggregate([
{ $group: {
_id: {
year: { $year: "$timestamp" },
month: { $month: "$timestamp" }
},
totalActions: { $sum: 1 },
uniqueUsers: { $addToSet: "$userId" }
}}
])
Common $group Operators
$sum: Calculate sums$avg: Calculate averages$minand$max: Find minimum and maximum values$addToSet: Create arrays of unique values$push: Create arrays of all values
Advanced Aggregation Techniques
Working with Arrays
MongoDB’s array operators are powerful tools for complex data processing:
db.orders.aggregate([
{ $unwind: "$items" },
{ $group: {
_id: "$items.product",
totalQuantity: { $sum: "$items.quantity" }
}}
])
Complex Calculations
The framework supports sophisticated computations:
db.transactions.aggregate([
{ $project: {
date: 1,
amount: 1,
taxAmount: { $multiply: ["$amount", 0.08] },
totalWithTax: { $multiply: ["$amount", 1.08] }
}}
])
Performance Optimization
Memory Usage Considerations
Understanding memory usage is crucial for optimizing your aggregation pipelines. Here are key points to consider:
- Pipeline Stage Order: Proper ordering can significantly reduce memory usage
- Document Size: Monitor and control the size of documents flowing through the pipeline
- Batch Processing: Consider processing data in smaller batches for large datasets
Best Practices and Tips
-
Pipeline Optimization
- Place
$matchand$limitstages early - Use
$projectto reduce data size - Avoid unnecessary stages
- Place
-
Resource Management
- Monitor memory usage
- Use indexes effectively
- Consider batch processing for large datasets

Real-World Examples
Time-Series Analysis
db.metrics.aggregate([
{ $match: {
timestamp: {
$gte: new Date("2024-01-01"),
$lt: new Date("2024-12-31")
}
}},
{ $group: {
_id: {
$dateToString: {
format: "%Y-%m",
date: "$timestamp"
}
},
avgValue: { $avg: "$value" },
maxValue: { $max: "$value" }
}},
{ $sort: { "_id": 1 }}
])
Geographic Analysis
db.stores.aggregate([
{ $geoNear: {
near: {
type: "Point",
coordinates: [-73.9667, 40.78]
},
distanceField: "distance",
maxDistance: 5000,
spherical: true
}},
{ $group: {
_id: "$type",
avgDistance: { $avg: "$distance" },
count: { $sum: 1 }
}}
])
Troubleshooting Common Issues
Memory Limitations
When dealing with memory limitations:
db.collection.aggregate([
// Your pipeline stages
], {
allowDiskUse: true
})
Performance Issues
To diagnose performance issues:
db.collection.aggregate([
// Your pipeline stages
], {
explain: true
})
Conclusion
The MongoDB Aggregation Framework is a powerful tool that transforms the way we process and analyze data. Whether you’re performing simple grouping operations or complex data transformations, understanding these concepts will help you build more efficient and effective data pipelines.
Remember these key takeaways:
- Start with simple pipelines and gradually add complexity
- Always consider performance implications
- Use appropriate indexes for your queries
- Monitor and optimize resource usage
- Test thoroughly with representative data volumes
Additional Resources
Remember, the key to mastering aggregation is practice. Start with simple pipelines and gradually incorporate more complex stages as you become comfortable with the basics. Happy aggregating!